 Bliv gratis medlem
Bliv gratis medlem

Hele konceptet omkring split-test er supercool. At man ved hjælp af data kan afprøve nye design op mod det eksisterende og med statistisk gyldighed måle hvad der virker. Tilsidesætte mavefornemmelser, say-do konflikter og andet menneskelig bias.
Absolut fortræffeligt!
I USA har det endda været populært at tale om split-test som den videnskabelige metode og alle kunne kækt tilføje "You should test that!" hver gang nogen kom med en kreativ idé: Død over best practice og tilsvarende dyrekøbte erfaringer - nu skal vi teste og måle os frem.
Og på mange måder er det hele korrekt og vanvittig interessant. Det er bare irriterende svært at få til at fungere i praksis. Du ved, hverdagen, der hvor du skal få de smarte tips og tricks til at give øget bundlinje.
Det er irriterende svært fordi der er en række indbyggede problemer i split-test. Dem skal jeg vende tilbage til.
I første omgang vil jeg gerne sige et par ting baseret på min erfaring med split-test over de sidste 10 år. Ikke at jeg har lavet split-test systematisk i 10 år - pointen her er netop, at det ikke er sket - men jeg har fulgt med på sidelinjen og har arbejdet med optimering af websitet i mere end de 10 der er gået siden jeg først blev introduceret til split-test.
Den ene ting er at luften i årevis har været tyk af bedrevidende konsulenter og bureauer, der har haft travlt med at fortælle at vi alle skal teste, samtidigt med at de har hylet op omkring at "95% do it wrong". Især på det engelsktalende marked (hvor jeg for øvrigt tror der bliver split-testet langt mere).
Derfor har jeg altid været bange for at gøre det forkert og er stadig i tvivl om mine resultater er kejserens nye klæder. Jeg anerkender at nogle ved meget mere om split-test end jeg gør og er åben overfor, at jeg kun står på en lokal tinde og ser nedad.
Med andre ord: Split-test er komplekst og der er mange muligheder for at få støj og fejl ind i testens resultater. Jeg prøver at håndtere det ved at være ydmyg og grundig.
Den anden ting er, at jeg er forbavset over hvor få virksomheder der har taget systematisk split-test (ja og systematisk optimering i det hele taget) til sig. Det er noget mine egne kunder efterspørger meget lidt og det er ikke noget der automatisk opstår i virksomhederne. På nogle områder er fortløbende optimering med systematiske test, stadig i sin spæde ungdom. Også selvom Amazon efter sigende har split-testet siden halvfemserne.
For nylig tilbød jeg gratis split-test til alle virksomheder der har trafik nok (40K sessioner om måneden). No-cure, no-pay - hvor der kun skal betales hvis split-testen har et positivt resultat. Og der er faktisk tale om at lægge 3-5 timer up front. Til gengæld skal man forpligte sig til minimum 3 test. Forretningsmodellen er, at jeg tror så meget på min egne evner (og metodikken) at jeg lægger hovedet på blokken i løbet 3 test.
0 virksomheder var interesserede. Nul.
Det kan der være mange grunde til. Mange gode grunde, fx at ingen så det opslag. Men det er da alligevel lidt pudsigt. Kvit og frit at få testet ting. Vi laver det hele i Google Optimize - du betaler kun hvis det giver plus. (Seneste kunde fik øget omsætning på 100.000 i testperioden og det kostede dem 5.000 til Optuner).
Nej tak. Ingen interesse.
Nå, det var et sidespor. Tilbage til at skyde dig i foden.
Lad os antage at jeg er en split-test hardliner. Jeg er hård i filten når det kommer til split-test. Det er jeg fordi jeg har sat mig ind i de statistiske beregninger (det er her du godt kan høre, at det bare er noget vi leger) - så jeg kender usikkerhederne og jeg forstår hvad det er beregningen gør.
Her er hvad hardlineren (blandt andet) vil sige:
- Hvis ikke dine split-test er statistisk gyldige, så må du ikke udpege en vinder, for du gør det med bind for øjnene. Implementerer du den vindende variation så skader du i værste fald din konvertering.
- Hvis du ikke segmenterer dine testresultater, så kan du ikke forvente at få det løft du fik i testen. Du kan nemlig ikke vide hvordan testens segmenter klarer sig. I værste fald implementerer du igen noget, hvor du ikke kender konsekvensen af ændringen.
Disse to udsagn er beviseligt korrekte. Har du ikke styr på de ting, så skyder du meget let dig selv i foden og du vil ofte opleve, at du ikke kan gense resultatet af din test når du har implementeret ændringen - noget jeg tror vi alle genkender.
De er også de to primære grunde til at "95% do it wrong".
Men de er også begge relativt enkle at få bugt med.
Lad mig tage dem en ad gangen:
Hvis din test ikke statistisk gyldig. Ok, tillad mig at forklare, bare hvis den del ikke står lysende klart for dig. Vi kører hele det her statistiske cirkus afsted, fordi vi laver en sandsynlighedsberegning. Ligesom ved et folketingsvalg. Vi spørger 1.000 mennesker hvordan de stemmer og så bruger vi de tal til at sige hvordan alle danskere stemmer. Vi propper altså de 1.000 danskere ind i en beregning og ud kommer nogle tal der siger noget om hvor sandsynligt det er at resultatet for alle danskere bliver sådan. En art matematisk forudsigelse, med en indbygget håndtering af den usikkerhed der i sagens natur er i den slags fremskrivninger.
Det samme med split-test. Vi hælder data ind i beregningen. Data om antal besøg og antal konverteringer. Vi kan ikke nøjes med at se på konverteringsraten i testperioden - selvom de tal jo uomtvisteligt fortæller hvordan det gik der - for de tal er kun repræsentative og beskriver netop kun den periode, ikke alle fremtidige brugere og deres konverteringsrate.
Den statistiske beregning siger generelt to ting: 1) Hvornår den har fået tal nok til at forskellen mellem kontrol og variation er statistisk gyldig (og gyldig her er blot et niveau man har besluttet). 2) Hvor stor usikkerheden er plus/minus for konverteringsraten på kontrol og variation.
Lidt kluntet kan man sige, at beregningen venter på at data for kontrol og variation statistisk set kan defineres til at være forskellige.
Skal vi respektere den beregning - for sådan helt matematisk at "måtte" sige noget om gyldigheden af vores test - så må vi vente. Nogle gange kommer der aldrig en forskel. Så kommer der ikke en vinder. Nogensinde.
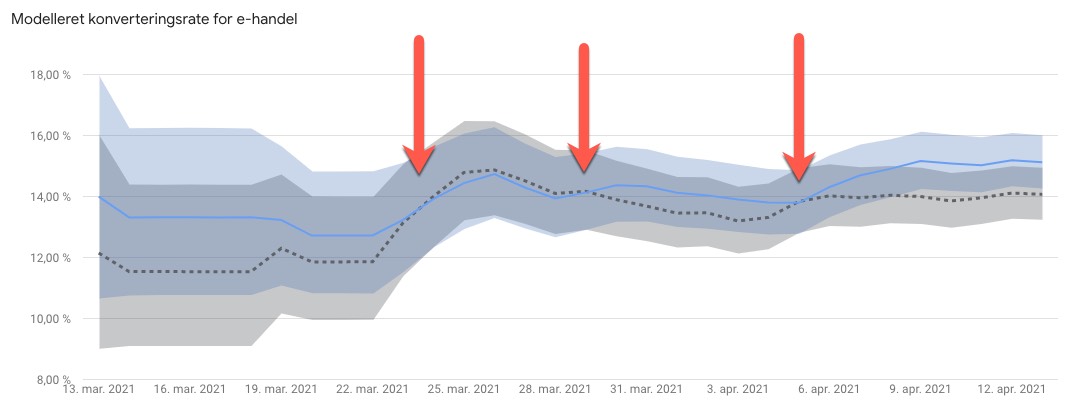
(Billedtekst: En pil for hver gang man kunne have dummet sig og kåret en vinder).
Det er derfor man skal have trafik nok og tid nok. Har man ikke det, så kan man principielt ligeså godt lade være (Ja eller bare sætte kvalitetskriteriet ned). Men jo mere man slækker på kravene, desto større er chancen for at det man ser i testen, aldrig kommer til at ske i en fremtidig virkelighed.
Lad mig tage den med segmenteringen med det samme (det var nummer 2). Stort set alle split-test værktøjer viser det samlede testresultat. Problemet er bare at forskellige segmenter af testdeltagernes har forskellig adfærd. Den hele store dark horse er enhedstypen, altså især om det er desktop eller mobil vi tester på.
Seneste test jeg gennemførte var der hele 10% forskel. Hvor desktop performede virkeligt godt, var der en lille negativ effekt på mobil. Så at implementere den variation, ville altså skade konverteringen på mobil. Og på nogle sites idag er vi oppe på 60-80% mobil trafik, så det er ikke ligegyldige forskelle.
De tools der bliver brugt mest i Danmark er Visual Website Optimizer (VWO) og Google Optimize (GO). Ingen af de to viser segmenterede testdata som standard. På VWO koster det kassen af få den feature med (pudsigt, ik?). På GO kræver det et hop over i Google Analytics. Ja, faktisk er Google Analytics løsningen. Også i VWO kan man lave en permanent løsning (med Tag Manager), så alle data er nemme at segmentere, uden at man skal sætte det op manuelt hver gang.
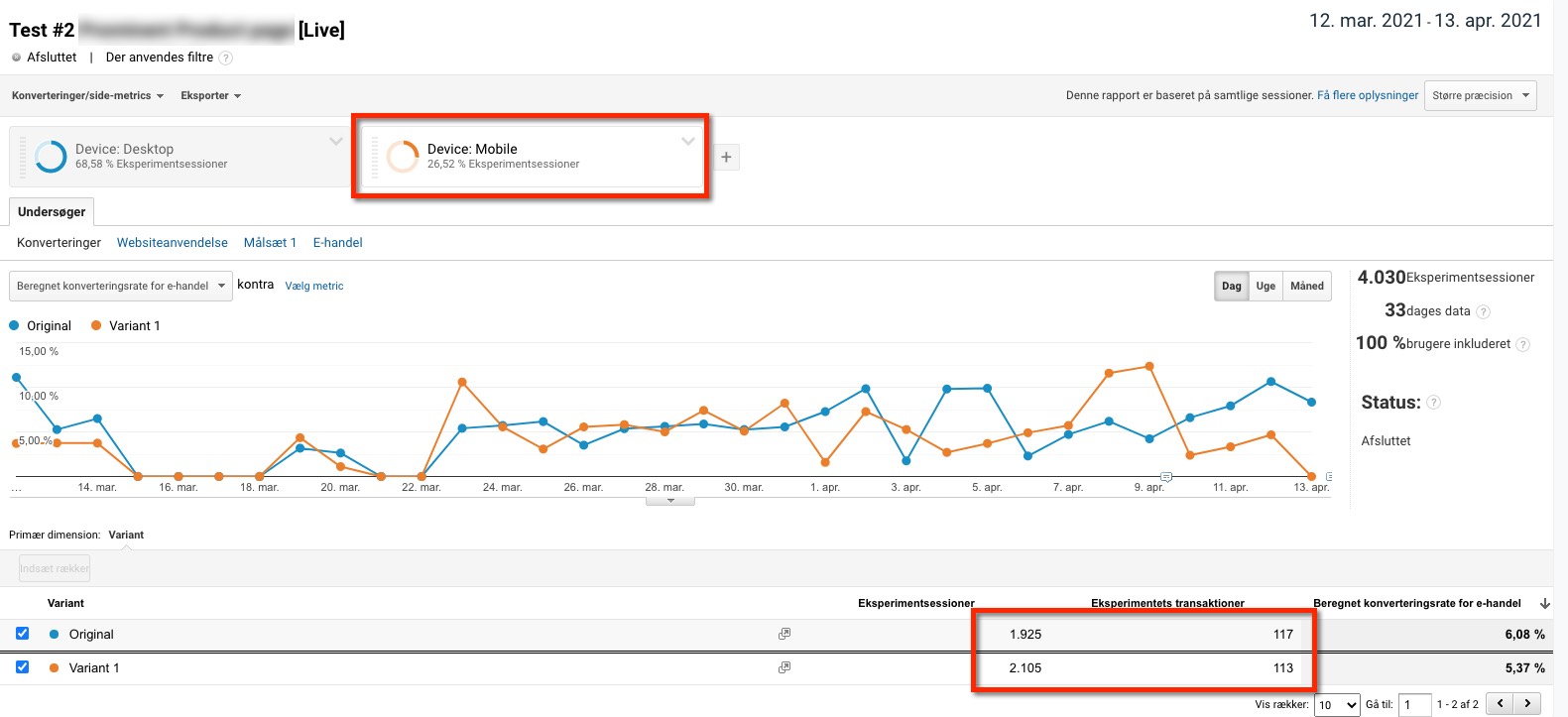
(Billedtekst: Relativt nemt at komme fra Google Optimize til at segmentere pr. device i Google Analytics - bare slå segmentet til og kopier data over i fx AB Testguide)
Når det først er lært, er det nemt at segmentere. Men man opdager så også et andet problem (og det bliver en gentagelse af punkt 1). For nu skal man ikke blot have data nok til 1 statistisk beregning, men til 2. Og man skal flytte data fra analytics og lave beregningerne er 3. sted. Men det er ikke rocket science, man skal bare lære det og man skal bare gøre det.
Så i stedet for fx 200-300 konverteringer pr. variation, så skal du nu have flere. Og hvis du kun har 30% mobiltrafik, ja så kan du nok regne ud at du skal have en del mere trafik for at komme op på flere hundrede konverteringer for mobil alene.
Noget du vil opleve, hvis det er nyt for dig at segmentere split-test er, at ganske ofte så er resultaterne kun statistisk gyldige for den ene enhedstype. Det er kan også være voldsomt provokerende. Så er der ikke andet at gøre end at vente.
Og det er hvis du kun segmenterer på desktop og mobil. Hvad nu vil du vil se på betalt trafik vs. SoMe trafik på mobil. Ja, du kan tænkte dig til resten. Men husk, når du ikke segmenterer, så kan der ligge overraskelser dernede i tallene og modarbejde dit forventede resultat.
Så ja. Det er nemt at skyde sig i foden: Kigge på sine test data for tidligt, kigge på dem samlet og ikke i segmenter, køre for korte test og generelt arbejde med små tal. Acceptér hvis du ikke har trafik nok og vælg nogle andre metoder.
Til dig der kan siger jeg. Jeg holder med dem der i grove træk siger: Kør en test om måneden, men kør dem så til gengæld også hver måned. Det er der ikke mange der gør, så jeg forventer at dem der gør, efter kort tid opbygger en viden og erfaring, der giver dem en klar konkurrencefordel.
