 Bliv gratis medlem
Bliv gratis medlem

Får du gode split-test resultater, så del dem. Læser du gode split-test resultater, så vær kritisk.
Man skal ikke skamme sig over gode split-test resultater. Så når vi rammer rigtigt, skal vi da fortælle hele verden om det. Vi skal dele vores succes - også så vi potentielt dækker over alle de gange vi har haft lyst til at kyle testen i skraldespanden ;-)
Så tillad mig lige at fyre en totalt klassisk test af her. Både for at vise hvad der kan lade sig gøre, men også for at understrege et par vigtige split-test leveregler.
Testen først
Som en del af et optimeringsprojekt for webshoppen Med24.dk, der handlede om at få flere besøgende til at blive medlemmer i Med24's klub, arbejdede vi med alle de trin der indgik i den konvertering. Indgangen, mod konverteringen til medlem, gik blandt andet igennem et banner placeret over hele sitet (på nær i tjek-ud forløbet).
Det var oplagt at udfordre om ikke vi kunne få flere til at klikke på banneret, lede dem ind i tragten og motivere dem til at blive medlemmer.
Fra kundeinterview og brugertest vidste vi, at det der motiverer besøgende til at blive medlem hos Med24 er rabat (fast procentsats for medlemmer) og vareprøver. Samtidigt var det oplagt at afprøve, om større synlighed for knappen ville ændre antallet der klikkede på den.
Så netop de to aspekter indgik som testhypoteser: Kan vi få flere klik ved at øge knappens form og farve - og derved kontrasten i relation til resten af sitet. Og kan vi øge antal klik ved at angive, at medlemskabet også giver gratis vareprøver.
Det gav en split-test med to variationer - de er vist her sammen med den originale knap:
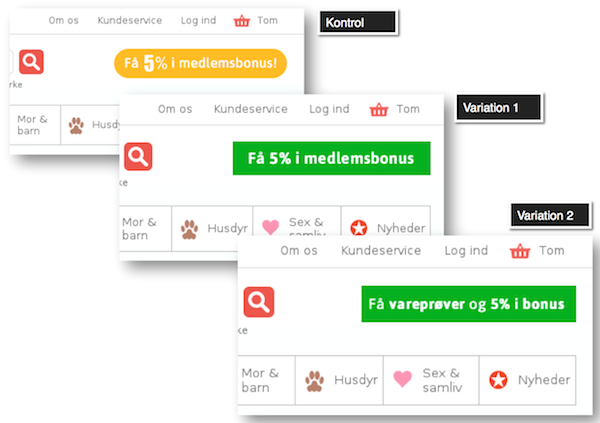
Så tænker du nok, at det er den klassiske test på bare at lave knappen grøn. Ja, det er det også, men pointen er, at alle de andre knapper allerede var orange. Grøn er komplimentærfarve til en orange og bruges andre steder på websitet til at markere handling. Så det var ikke "bare" at prøve en grøn.
Men samtidigt har du ret. Det er den klassiske orange versus grøn test. Det er det der gør det så lækkert. At nogle gange, så ja, så virker det.
Her er resultatet fra split-testen fra VWO:
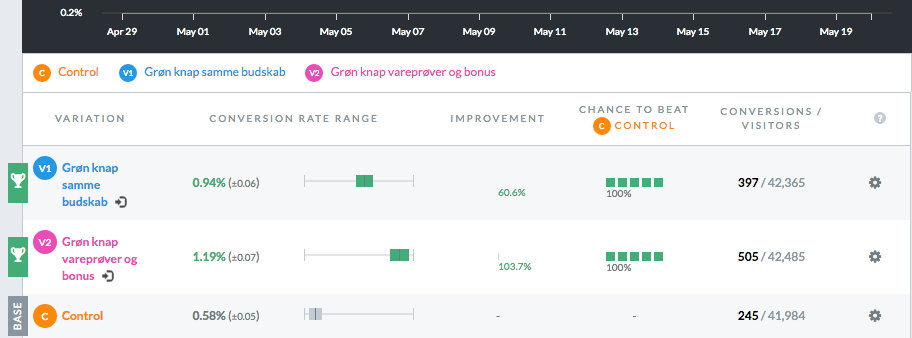
En stigning på over 100% - altså på antal klik på knappen. (Vi ved fra analytics at Med24 også har dobbelt så mange visninger af medlemssiden og antallet af nye medlemmer er steget 22% mellem sammenlignelige kvartaler før og efter testen - men det er altså ikke det, testen målte).
Bemærk, at jeg med rank ryg fremviser at testen har kørt i mere end 3 uger (for at kunne sammenligne 3 "rene" uger med data i Google Analytics), at antallet af konverteringer ligger mellem 250 og 500 og at den statistiske validitet ifølge VWO er 99%. Testen er kørt på al trafik. Vi har efterfølgende segmenteret data i Google Analytics.
For det er vigtigt når du læser artikler som den her. At du holder øje med, om tallene bag testen bliver delt med dig og hvad tallene faktisk dækker over. Selv i ovenstående eksempel er der masser du kan udfordre: Testen viser resultatet for alle trafikkilder og for alle typer enheder. Men det er ikke ligemeget fx hvilken betalt trafik der ledte brugerne ind på sitet. Hvad nu hvis de fx er blevet lovet vareprøver i en kampagne? Hvad nu hvis knappen sad helt "noller" i mobilversionen?
Pas på du ikke snyder dig selv. Hvad Med24 og jeg gør med dette resultat er vores egen beslutning, men hvis du blindt kopierer testen, så risikerer du at skyde dig selv i foden.
Jeg bliver sgu lidt knotten
Det er derfor jeg lige skal bringe mit pis i kog en gang mere og råbe vagt i gevær. Jeg har nemlig lidt svært ved ikke at blive knotten når jeg læser split-test resultater, hvor der tydeligt er alt for få data til rådighed. Både for få til at konkludere noget og for få til at vi som læsere kan stole på resultatet.
For en uges tid siden (og denne tekst er skrevet i uge 1), præsenterede et velkendt navn her på nettet en split-test case der efter sigende gav et løft på 30%. Det er et flot resultat og må udløse både en bonus og en forfremmelse. Men læste man teksten, var der især to ting der generede mig.
For det første var testen baseret på kun 2 dages split-test. 2 dage!
Vi er mange der har sidder med Visual Website Optimizer og glædet os over flotte tal de første par dage, blot for at se testen stabilisere sig og ende i noget helt andet. Der findes også mange eksempler på test, hvor "taber" og "vinder" bytter plads i løbet af testen. Der er efterhånden også mange blogindlæg fra meget respekterede konsulenter, der peger på at test skal køre - ja, længere end 2 dage. Så at udråbe sig selv og sin test til vinder efter 2 dage - det mener jeg ikke er troværdigt.
For det andet: Samme test viser et skærmbillede fra VWO, ligesom jeg har gjort ovenfor, men antallet af konverteringer er visket ud. Hvorfor det? Er det mon fordi det ikke er særligt stort? Jeg mener ikke jeg kan bebrejdes for at få den mistanke. Hvis testen er lavet ordentligt, så gemmer der sig 2-300 konverteringer under det blur. Jeg vælger at tro det ikke er tilfældet.
Ok Surepoul hvad er din pointe?
Min pointe er: Jeg tror ikke på de 30% i den artikel. Jeg føler et indre behov for at sige til dig, at du heller ikke skal tro på det. I bedste fald er artiklen misvisende og kan skabe falske konklusioner, i værste fald er det jo bare en form for løgn.
Kildekritik trives rigtigt dårligt i sociale medier, blogs og på nettet generelt - så der for skal vi selv være kritiske. Derfor et par tommelfingerregler når du læser split-test cases:
- Er der adgang til data? Som minimum testens varighed, antal besøg/konverteringer, statistisk signifikans.
- Hold øje med hvad testen reelt måler. Tænk på om der er "støj" i resultatet, fx at der tales om den endelige konvertering, selvom testen kun måler antal klik på forsiden. Tænk over forholdet mellem den ændring der er foretaget og så den interaktion der er foregået. Kan man med rette antage at der er en direkte sammenhæng mellem de to? Hvis ikke, så kan resultatet være udtryk for noget helt andet.
- Er der noget viden om hvilken trafik der indgår i testen, er det fx al trafik eller kun organisk trafik, er det kun desktop eller også mobil? Eller endnu bedre, kan det påvises at resultatet holder, selv efter en segmentering af fx betalt og ikke betalt trafik?
Her er et par links til artikler der udpensler problematikken:
http://conversionxl.com/12-ab-split-testing-mistakes-i-see-businesses-make-all-the-time/ (se punkt 1)
http://blog.crazyegg.com/2015/07/14/split-testing-is-off/
I planlægningen af den kommende ConversionBoost konference om konverteringsoptimering, taler vi meget om at sikre kvaliteten på samme måde. Vi arbejder på, at oplægsholderne deler deres resultater og udfordrer dem på resultaternes kvalitet. Det er vigtigt for os alle sammen her på nettet, at vi hele tiden udfordrer vores test, vores resultater og hinanden på den kvalitet. For troværdige data og brugen af dem er en central del af konverteringsoptimering.
God fornøjelse med split-test og læselyst i det nye år.
